Statistical inference within distributed or cloud data ecosystem
According to the Harvard Business School Online, the term data ecosystem refers to the programming languages, packages, algorithms, cloud-computing services, and general infrastructure an organization uses to collect, store, analyze, and leverage data. The data ecosystem has become increasingly complex in order to efficiently analyze excessively large datasets that arise with the business activities and the advance of technology. Challenges arise when one wants to perform sophisticated statistical analysis within a complex data ecosystem.
The price of operating in a complex data ecosystem, where data are usually stroed in cloud or in distributed computing system, is positively associated with the number of passes over the entire dataset of interest. Unfortunately, popular numerical routines usually require many passes. For example, one gradient descent iteration typically requires one pass over the entire dataset, and fitting a logistic regression can take hundreds or thousands of iterations. In addition, in data science practice, one often needs multiple querries over the entire dataset in order to perform a certain task. Passes over entire data is not only costly but also inefficient as computational overhead may occur. Hence, minimizing the number of queries without sacrificing statistical accuracy is most desirable in practice.
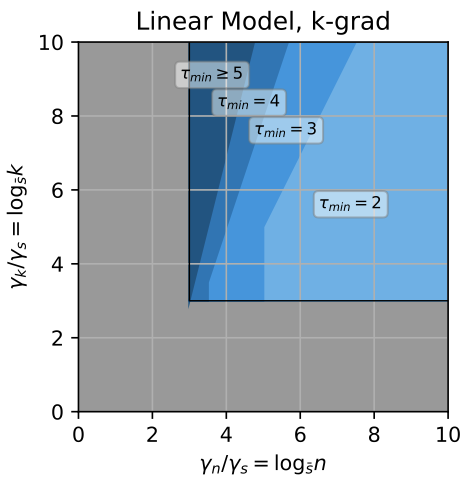
My research goal is thus to develpe provable methods that can be performed with one or just a few passes over the entire dataset while maintaining oracle inferential accuracy such as size and power. Our main theoretical output, the minimal number of passes $\tau_{\min}$ over entire dataset, often depend on the type of models, e.g. linear or logistic regression model, complexity (dimensionality) and the computational power. Our methods can be used to perform inference for regression models, e.g. linear, logistic regression or even quantile regression.
My vision is to create methods that can be seamlessly integrated into the daily data science applications hosted in cloud or distributed computational framework, for example using large user data with billions of entries to test the effect after a feature in an app is introduced.